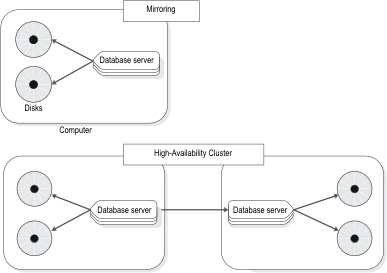
Clustering versus mirroring
Clustering and mirroring are transparent methods for increasing fault tolerant.
Mirroring, described Mirroring, is the mechanism by which a single database server maintains a copy of a specific dbspace on a separate disk. This mechanism protects the data in mirrored dbspaces against disk failure because the database server automatically updates data on both disks and automatically uses the other disk if one of the dbspaces fails.
Alternatively, a cluster duplicates on an entirely separate database
server all the data that a database server manages, not just the specified dbspaces.
Because clustering involves two separate database servers, it protects
the data that these database servers manage, not just against disk
failures, but against all types of database server failures, including
a computer failure or the catastrophic failure of an entire site.
Figure 1. A comparison of mirroring
and clustering