Data-distribution cache
The query optimizer uses distribution statistics generated by the UPDATE STATISTICS statement in the MEDIUM or HIGH mode to determine the query plan with the lowest cost. The first time that the optimizer accesses the distribution statistics for a column, the database server retrieves the statistics from the sysdistrib system catalog table on disk and places that information in the data-distribution cache in memory.
Figure 1 shows how
the database server accesses the data-distribution cache for multiple
users. When the optimizer accesses the column distribution statistics
for User 1 for the first time, the database server puts the distribution
statistics in the data-distribution cache. When the optimizer determines
the query plan for user 2, user 3 and user 4 who access the same column,
the database server does not have to read from disk to access the
data-distribution information for the table. Instead, it reads the
distribution statistics from the data-distribution cache in shared
memory.
Figure 1. Data-distribution cache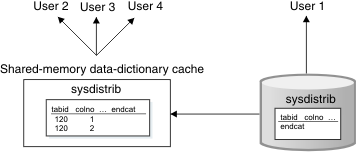
The database server initially places pages for the sysdistrib system
catalog table in the buffer pool as it does all other data and index
pages. However, the data-distribution cache offers additional performance
advantages. It:
- Is organized in a more efficient format
- Is organized to allow fast retrieval
- Bypasses the overhead of the buffer pool management
- Frees more pages in the buffer pool for actual data pages rather than system catalog pages
- Reduces I/O operations to the system catalog table